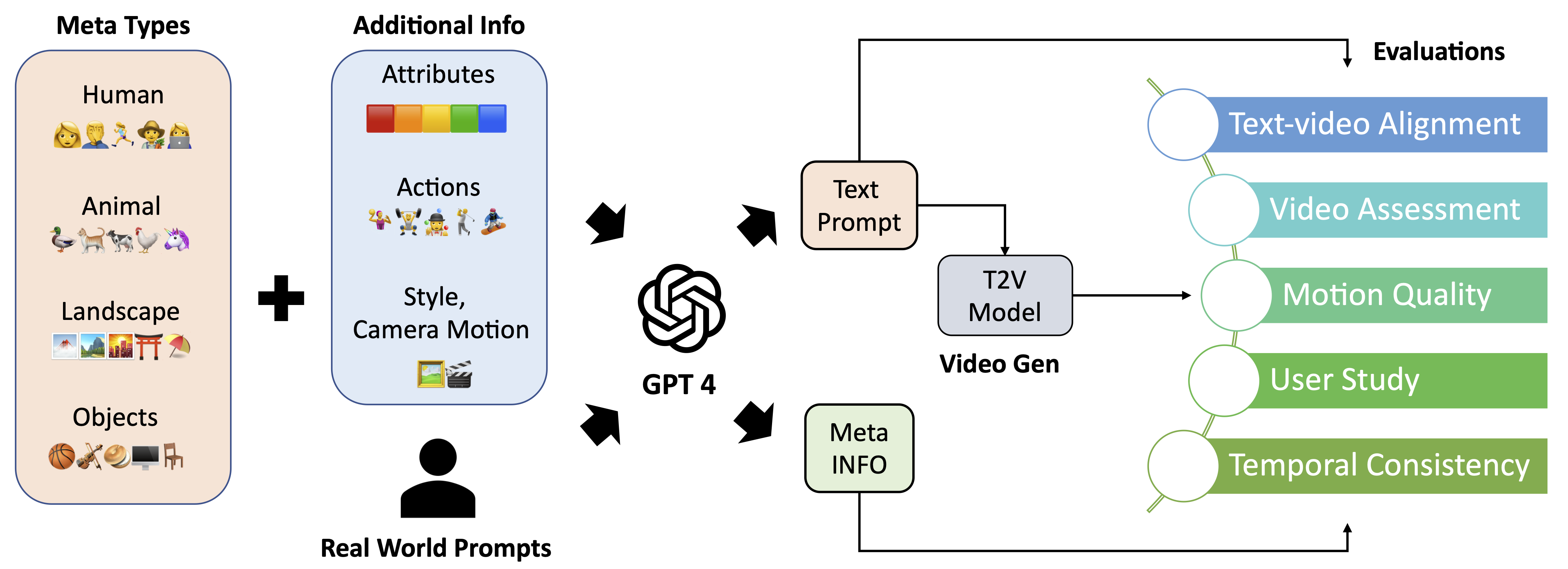
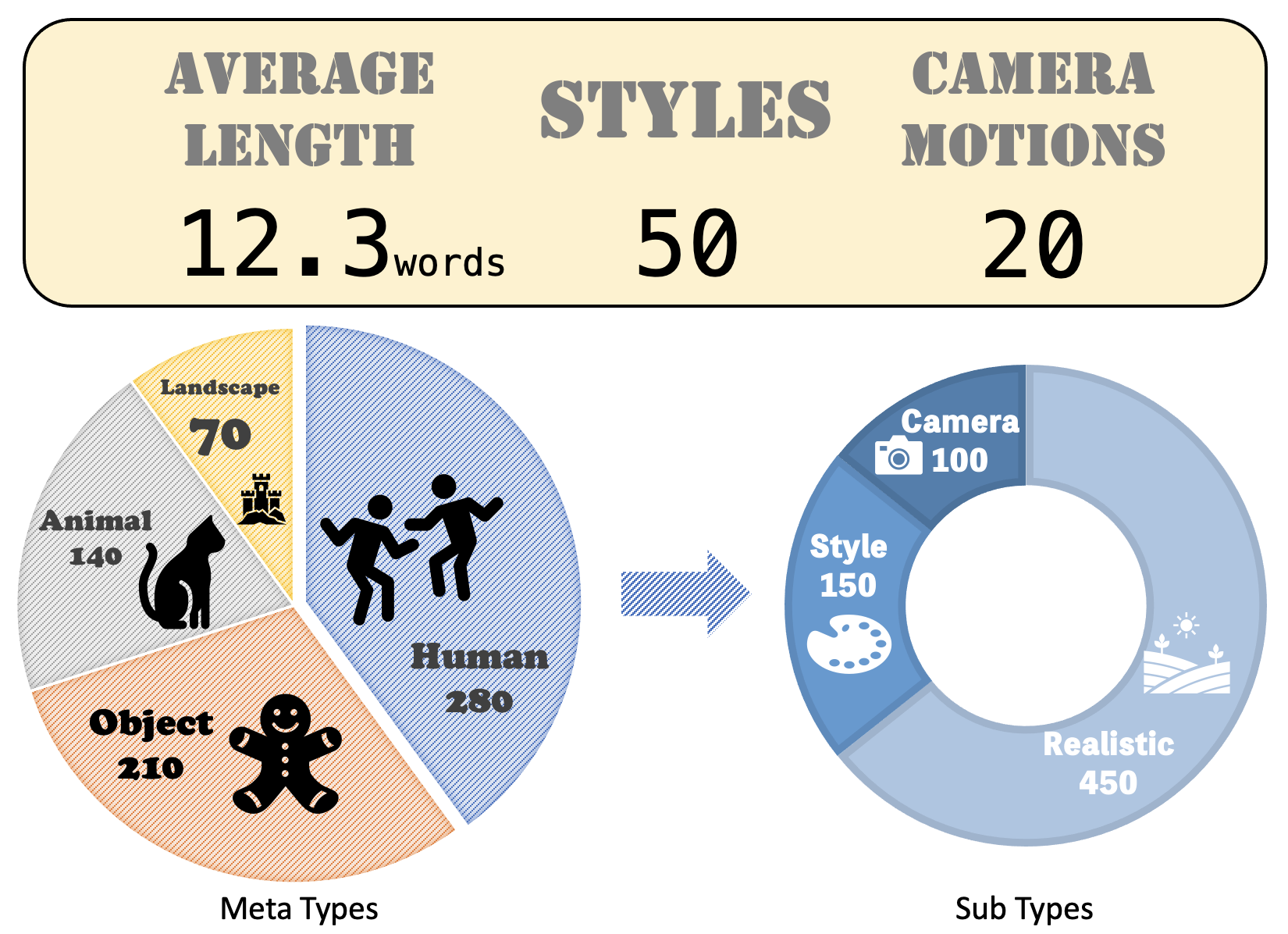
The vision and language generative models have been overgrown in recent years. For video generation, various open-sourced models and public-available services are released for generating high-visual quality videos. However, these methods often use out-of-fashion academic metrics, \eg, FVD or IS, to evaluate the models' performance. We argue that it is hard to judge the large conditional generative models from the simple metrics since these models are often trained on very large datasets with multi-aspect abilities. Thus, we propose a new framework and pipeline to exhaustively evaluate the performance of the generated videos. To achieve this, we first conduct a new prompt list for text-to-video generation by analyzing the real-world prompt list with the help of the large language model. Then, we evaluate the state-of-the-art text-to-video generative models on our carefully designed benchmarks, in terms of visual qualities, content qualities, motion qualities, and text-caption alignment with around 17 objective metrics. To obtain the final leaderboard of the models, we also conduct 5 subjective studies from the aspective of motion quality, text-video alignment, temporal consistency, visual quality, and user favor, where we can align the objective metrics to the users' opinions and get the final ranking. Based on the proposed opinion alignment method, our method can successfully align the objective metrics to the subjective ones and show the effectiveness of the proposed evaluation metrics.
| Name | Version | Abilities | Resolution | fps | Open Source | Length | Generation Speed | Motion Control | Camera Control |
|---|---|---|---|---|---|---|---|---|---|
| ModelScope | 23.03 | T2V | 256x256 | 8 | ✅ | 4s | 0.5min | - | - |
| Gen2 | 23.09 | I2V OR T2V | 896x512 | 24 | - | 4s | 1 min | ✅ | ✅ |
| LaVie-Interpolation | 23.09 | T2V | 1280x2048 | 8 | ✅ | 2s | 3 min | - | - |
| PikaLab | 23.09 | I2V OR T2V | 1088x640 | 24 | - | 3s | 1 min | ✅ | ✅ |
| Hotshot-XL | 23.10 | T2V | 672x384 | 8 | ✅ | 1s | 10 s | - | - |
| LaVie-Base | 23.09 | T2V | 320x512 | 8 | ✅ | 2s | 10 s | - | - |
| VideoCrafter1 | 23.10 | I2V & T2V | 1024x576 | 8 | ✅ | 2s | 3 min | - | - |
| Show-1 | 23.10 | T2V | 576x320 | 8 | ✅ | 4s | 10 min | - | - |
| Floor33 | 23.08 | T2V | 1280x720 | 8 | - | 2s | 4 min | - | - |
| ModelScope | 23.08 | I2V & V2V | 1280x720 | 8 | ✅ | 4s | 8 min+ | - | - |
| ZeroScope | 23.06 | T2V & V2V | 1024x576 | 8 | ✅ | 4s | 3 min | - | - |
| Gen2 | 23.12 | I2V OR T2V | 1408x768 | 24 | - | 4s | 1.5 min | ✅ | ✅ |
| PikaLab V1.0 | 23.12 | I2V OR T2V | 1280x720 | 24 | - | 3s | 1.5 min | ✅ | ✅ |
| MoonValley | 24.01 | I2V OR T2V | 1184x672 | 50 | - | 1s | 3 min | - | ✅ |
| Metrics | Version | VQA_A | VQA_T | IS | CLIP-Temp | Warping Error | Face Consistency | Action-Score | Motion AC-Score | Flow-Score | CLIP-Score | BLIP-BLUE | SD-Score | Detection-Score | Color-Score | Count-Score | OCR-Score | Celebrity ID Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
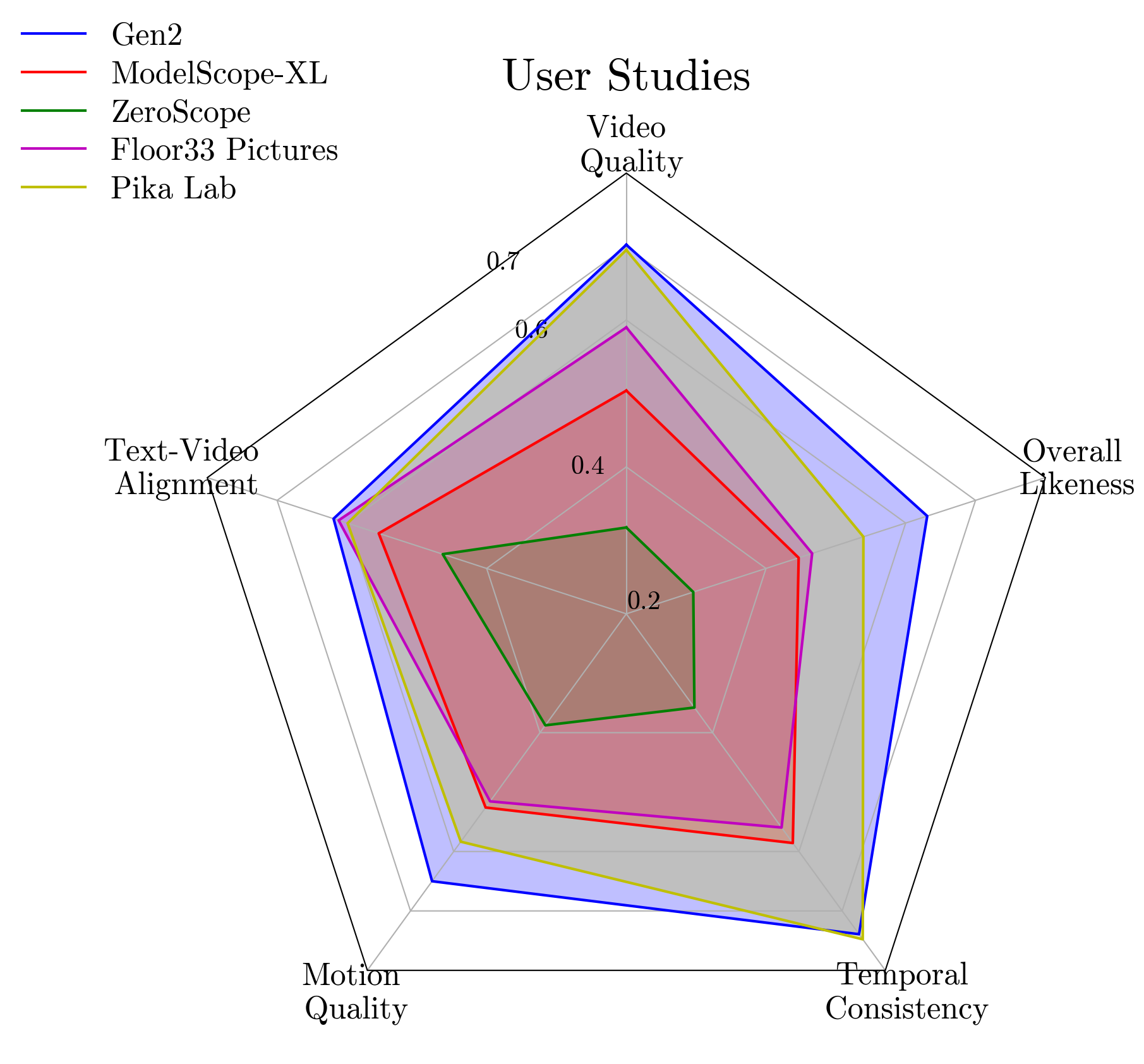
| Gen2 | 23.09 | 59.44 | 76.51 | 14.53 | 99.94 | 0.0008 | 99.06 | 62.53 | 44.0 | 0.7 | 20.53 | 22.24 | 68.58 | 64.05 | 37.56 | 53.31 | 75.0 | 41.25 |
| ModelScope | 2023.08 | 40.06 | 32.93 | 17.64 | 99.74 | 0.0162 | 98.94 | 72.12 | 42.0 | 6.99 | 20.36 | 22.54 | 67.93 | 50.01 | 38.72 | 44.18 | 71.32 | 44.56 |
| PikaLab | 2023.10 | 59.09 | 64.96 | 14.81 | 99.97 | 0.0006 | 99.62 | 71.81 | 44.0 | 0.5 | 20.46 | 21.14 | 68.57 | 58.99 | 34.35 | 51.46 | 84.31 | 45.21 |
| Floor33 | 2023.08 | 58.7 | 52.64 | 17.01 | 99.6 | 0.0413 | 99.08 | 71.66 | 74.0 | 9.26 | 21.02 | 22.73 | 68.7 | 52.44 | 41.85 | 58.33 | 87.48 | 40.07 |
| ZeroScope | 2023.06 | 34.02 | 39.94 | 14.48 | 99.84 | 0.0193 | 99.33 | 67.56 | 50.0 | 4.5 | 20.2 | 21.2 | 67.79 | 53.94 | 39.25 | 41.01 | 82.58 | 46.93 |
| VideoCrafter | 2023.10 | 66.18 | 58.93 | 16.43 | 99.78 | 0.0295 | 99.48 | 68.06 | 50.0 | 5.44 | 21.33 | 22.17 | 68.73 | 67.67 | 45.11 | 58.11 | 88.04 | 40.18 |
| Show-1 | 2023.10 | 23.19 | 44.24 | 17.65 | 99.77 | 0.0067 | 99.32 | 81.56 | 50.0 | 2.07 | 20.66 | 23.24 | 68.42 | 58.63 | 48.55 | 44.31 | 58.97 | 37.93 |
| Hotshot | 2023.10 | 71.54 | 50.52 | 17.29 | 99.74 | 0.0091 | 99.48 | 66.8 | 56.0 | 5.06 | 20.33 | 23.59 | 67.65 | 45.7 | 42.39 | 49.5 | 63.66 | 38.58 |
| MoonValley | 2024.01 | 93.2 | 90.02 | 14.55 | 99.97 | 0.0009 | 99.52 | 74.99 | 45.45 | 0.4 | 20.67 | 21.67 | 68.29 | 63.8 | 36.84 | 45.47 | 92.66 | 48.86 |
| Gen2 | 2023.12 | 90.39 | 92.18 | 19.28 | 99.99 | 0.0005 | 99.35 | 73.44 | 44.0 | 0.58 | 20.26 | 22.25 | 67.69 | 69.54 | 47.39 | 58.36 | 63.74 | 38.9 |
| PikaLab V1.0 | 2023.12 | 69.23 | 71.12 | 16.67 | 99.89 | 0.0008 | 99.22 | 61.29 | 42.0 | 1.14 | 20.47 | 21.31 | 67.43 | 70.26 | 42.03 | 62.19 | 94.85 | 36.53 |
A larger value indicate a better performance in nearly all the metrics.
Lower Warping Error means the better.
Amp Class means the motion amplitude classification score, which is only for reference.

@article{liu2023evalcrafter,
title={EvalCrafter: Benchmarking and Evaluating Large Video Generation Models},
author={Yaofang Liu and Xiaodong Cun and Xuebo Liu and Xintao Wang and Yong Zhang and Haoxin Chen and Yang Liu and Tieyong Zeng and Raymond Chan and Ying Shan},
year={2023},
eprint={2310.11440},
archivePrefix={arXiv},
primaryClass={cs.CV}
}